




How We Cut Astro Build Time from 30 Minutes to 5 Minutes (⚡ 83% Faster!)
We often find ourselves in a need to download multiple files/folders as a zipped file from an S3 bucket. However, there is no direct functionality in AWS S3 bucket that allows us to do that yet.
I was in need to zip & download multiple files from the bucket. Before using the method I am about to demonstrate, I tried using a method in which the files are first downloaded to either an EFS or tmp folder (limited to 512MB) and then zipping it via an archiver. However, that method was very taxing, complicated, slower & did not work well.
I then discovered this blog which narrated how we have a direct buffer to the stream so no disk memory is involved whatsoever. This intrigued me as most of my complications were resolved if I didn’t have to use the disk memory.
I will now do a walkthrough on how to zip files from S3 bucket & store the zipped-file back into S3 bucket. Further, we will also be seeing how to set up and use lambda layers from serverless in this blog post.
To create a serverless template for nodejs, we use the below command
serverless create --template aws-nodejs
We will be using Lambda functions, S3 buckets, IAM roles, and Lambda layers for this task. Below is how the serverless yalm file will look. We have included the layers for zipping (archiver) & for streaming (stream).
provider:
name: aws
runtime: nodejs12.x
region: us-west-2
iamRoleStatements:
- Effect: "Allow"
Action:
- "s3:PutObject"
- "s3:ListBucket"
- "s3:GetObject"
- "s3:PutObjectAcl"
Resource:
Fn::Join:
- ""
- - "arn:aws:s3:::"
- Ref: TestBucket
- "/*"
layers:
archiver:
#refer as ArchiverLambdaLayer
path: ./Layers/archiver
stream:
#refer as StreamLambdaLayer
path: ./Layers/stream
Zip:
handler: Zip/index.handler
layers:
- { Ref: ArchiverLambdaLayer }
- { Ref: StreamLambdaLayer }
The index handler sends out an object of parameters to the streamer. The parameter list would look like:
const param = {
files: [
{
fileName: "excel/1.xlsx", // prefix followed by file name
key: "excel/1.xlsx", // prefix followed by key name
},
{
fileName: "excel/2.xlsx",
key: "excel/2.xlsx",
},
],
zippedFileKey: "zip/zippedFile.zip", // prefix followed by file name
}
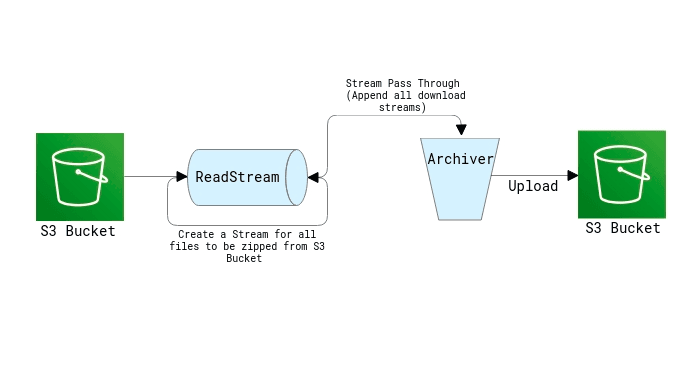
Next, we will create Read Stream for all the output files (filenames).
const s3FileDwnldStreams = params.files.map(item => {
const stream = s3.getObject({ Key: item.key }).createReadStream()
return {
stream,
fileName: item.fileName,
}
})
We now need to create a zip archive using streamPassThrough and link the request to S3.
const streamPassThrough = new Stream.PassThrough()
const uploadParams = {
ACL: "public-read", //change to private as per requirement
Body: streamPassThrough,
ContentType: "application/zip",
Key: params.zippedFileKey,
}
const s3Upload = s3.upload(uploadParams, (err, data) => {
if (err) console.error("upload error", err)
else console.log("upload done", data)
})
const archive = Archiver("zip", {
zlib: { level: 0 },
})
archive.on("error", error => {
throw new Error(
`${error.name} ${error.code} ${error.message} ${error.path} ${error.stack}`
)
})
We can also use the following command to track the progress of the upload.
s3Upload.on("httpUploadProgress", progress => {
console.log(progress)
})
Our last step would be to connect the archiver and streamPassThrough to pipe all the download streams to the archiver.
await new Promise((resolve, reject) => {
s3Upload.on("close", resolve())
s3Upload.on("end", resolve())
s3Upload.on("error", reject())
archive.pipe(streamPassThrough)
s3FileDwnldStreams.forEach(s3FileDwnldStream => {
archive.append(s3FileDwnldStream.stream, {
name: s3FileDwnldStream.fileName,
})
})
archive.finalize()
}).catch(error => {
throw new Error(`${error.code} ${error.message} ${error.data}`)
})
Reference
https://dev.to/lineup-ninja/zip-files-on-s3-with-aws-lambda-and-node-1nm1









