

 ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI Whenever you think of a chatbot, the first thing that comes to your mind is continuity. Your current question is always the continuation of the previous question. This flow is what essentially defines a chatbot. A virtual entity designed to maintain context and engage in dynamic conversation with the end user.
In my previous blog, I built a QA system with OpenAI, Pinecone, Lambda etc. Here in this blog, we are going to go a step further and complete the application by adding chat memory, an exciting feature that empowers chatbots to remember context, maintain a sense of history, and engage users in more natural and human-like conversations.
What is Chat Memory?
Chat memory in a chatbot is the ability to remember the previous interactions, exchanges with the user. The chatbot will have the context from these past interactions which can be useful while providing responses to the user. Langchain offers a variety of memory components to build conversational applications. In this blog, we will use Langchain's DynamoDB chat memory integration for the application. Following my previous blog, we have already built a QA application with Pinecone and OpenAI. To complete this application with chat memory, we need to build a tool to retrieve relevant data from Pinecone, build an Agent which is integrated with the vectorstore retriever tool and attach it with DynamoDB Chat Memory.
Let's get started.
First, we will build a retriever that will fetch us relevant text/documents for our query.
import pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
pinecone.init(api_key=pinecone_key, environment=pinecone_env)
index = pinecone.Index('openai')
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vectordb = Pinecone(index, embedding_function=embeddings.embed_query, text_key="text")
Then, we'll initialize the Chat Model,
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
temperature=0,
model_name = "gpt-3.5-turbo-16k",
streaming=True,
callbacks=[FinalStreamingStdOutCallbackHandler()]
)
Now, we create the retirever and use it as a Tool for the chatbot,
from langchain.chains import RetrievalQA
from langchain.agents import Tool
retriever = RetrievalQA.from_chain_type(
llm=chat,
chain_type="stuff",
retriever=vectordb.as_retriever(),
)
tool_desc = """Use this tool to answer user questions using AntStack's data. This tool can also be used for follow up questions from the user"""
tools = [Tool(
func=retriever.run,
description=tool_desc,
name='AntStack DB'
)]
Lot of things to unpack here. When we are setting up the retriever, we set chain_type to "stuff". Stuff here refers to a method of passing retrieved documents to an LLM. In this approach, all the retrieved documents are included in the prompt given to the LLM.
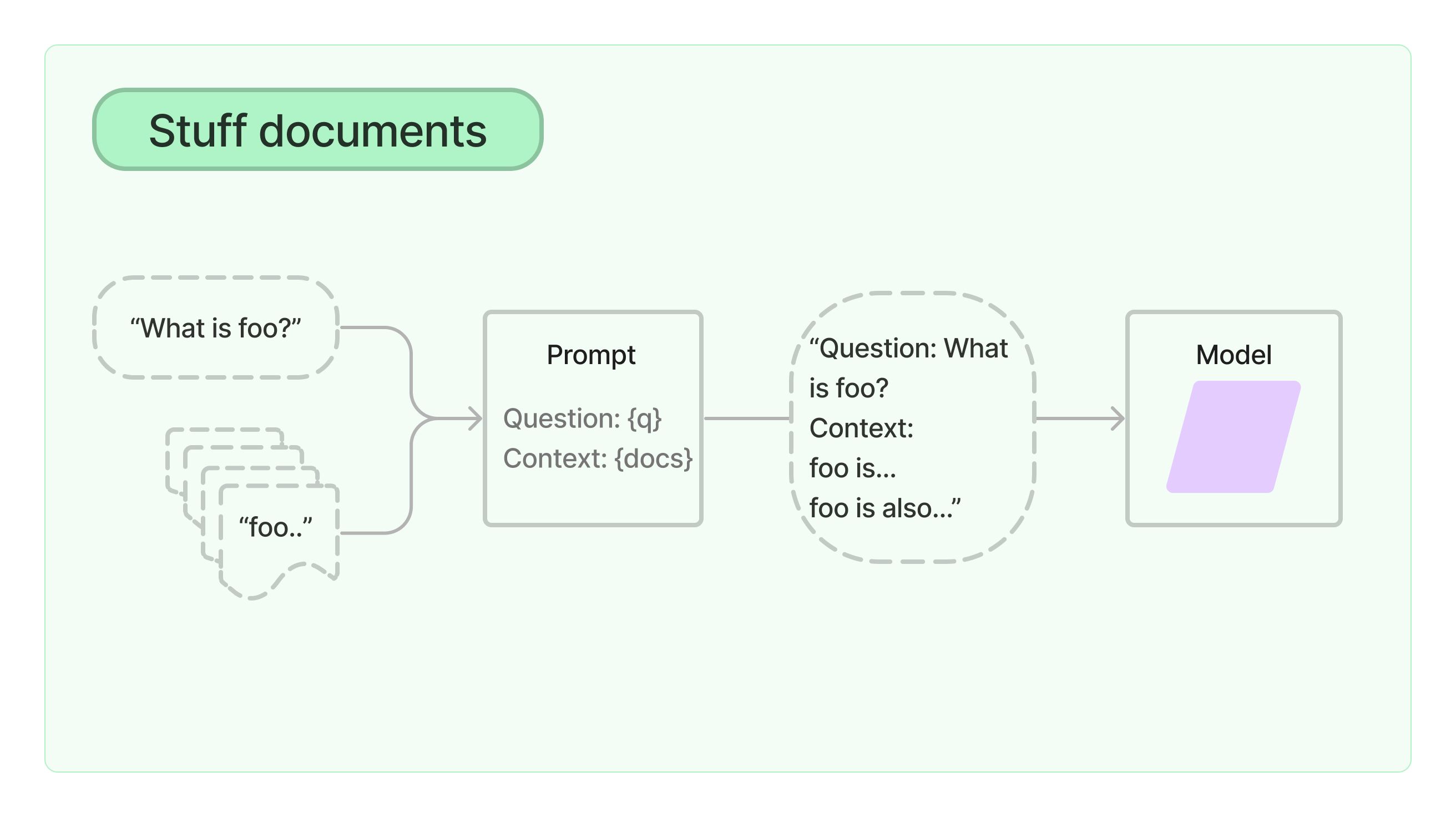
It also has vectordb.as_retriever() to fetch context from Pinecone, which we set up earlier. When we are configuring tools, we set func=retriever.run which essentially runs the retriever to fetch documents whenever this tool is executed.
Moving on, now it's time to setup the memory and the conversational agent. We need a DynamoDB table in order to use Langchain's DynamoDB memory feature. Go to DynamoDB Console and create a table with SessionId as the Primary Key.
For memory, we will make use of ConversationBufferMemory and use DynamoDB for our chat history. Visit here to know more about it. Then we initialize and agent that answers to our queries.
from langchain.memory import DynamoDBChatMessageHistory
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.agents import initialize_agent
from langchain.agents import AgentType
chat_history = DynamoDBChatMessageHistory(table_name='conversation-store', session_id='1234')
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
memory.chat_memory = chat_history
conversational_agent = initialize_agent(
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
tools=tools,
llm=chat,
verbose=False,
memory=memory,
)
Make sure that your local system is configured with AWS Security Credentials in order for the DynamoDB Chat History to work.
When we initialize our agent, we set the agent type to CHAT_CONVERSATIONAL_REACT_DESCRIPTION, which is a tool in LangChain agents that combines the power of an LLM with a retrieval-based question answering system, it uses a ChatOpenAI model for generating responses and a vector store for retrieving relevant documents.
At last, we set the System Message for the chatbot,
sys_msg = """You are a chatbot for a Serverless company AntStack and strictly answer the question based on the context below, and if the question can't be answered based on the context, say \"I'm sorry I cannot answer the question, contact connect@antstack.com\"
"""
prompt = conversational_agent.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
conversational_agent.agent.llm_chain.prompt = prompt
Now, let's ask some questions,
conversational_agent.run("What is AntStack?")
A: 'AntStack is a Serverless company that provides solutions and services for building and deploying applications on the cloud. They specialize in serverless architecture, which allows developers to focus on writing code without worrying about infrastructure management.'
conversational_agent.run("What else do they do?")
A: 'AntStack also provides consulting and training services to help organizations adopt and implement serverless architecture effectively.'
And of course, if you want to deploy it as a SAM application, here's the SAM template:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
Langchain-DynamoDB
Sample SAM Template for Langchain-DynamoDB
Globals:
Function:
Timeout: 30
MemorySize: 512
Resources:
MyHttpApi:
Type: AWS::Serverless::HttpApi
Properties:
StageName: Prod
CorsConfiguration:
AllowMethods:
- '*'
AllowOrigins:
- '*'
AllowHeaders:
- '*'
ConvTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: SessionId
AttributeType: S
KeySchema:
- AttributeName: SessionId
KeyType: HASH
BillingMode: PAY_PER_REQUEST
ChatFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: chat/
Handler: app.lambda_handler
Runtime: python3.10
Policies:
- AWSLambdaBasicExecutionRole
- DynamoDBCrudPolicy:
TableName: !Ref ConvTable
- AmazonSSMReadOnlyAccess
Environment:
Variables:
MESSAGE_HISTORY_TABLE: !Ref ConvTable
Layers:
- !Ref ChatLayer
Events:
chat:
Type: HttpApi
Properties:
ApiId: !Ref MyHttpApi
Path: /chat
Method: post
ChatLayer:
Type: AWS::Serverless::LayerVersion
Properties:
ContentUri: chat/
CompatibleRuntimes:
- python3.10
Metadata:
BuildMethod: python3.10
Outputs:
MyHttpApi:
Description: "API Gateway endpoint URL for Prod stage for MyHttpApi function"
Value: !Sub "https://${MyHttpApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/chat"
Notice here that I'm not deploying the Lambda with ECR like I did in my previous blog. In my Layer under Metadata, I've mentioned BuildMethod: python3.10 which installs all the libraries mentioned in the requirements and deploys the lambda. This only works if the libraries are less than 250MB. Below is the requirements.txt.
langchain
openai
urllib3==1.26.13
pinecone-client
The code for Lambda:
import boto3
import pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.callbacks.streaming_stdout_final_only import (
FinalStreamingStdOutCallbackHandler,
)
from langchain.chains import RetrievalQA
from langchain.agents import Tool
from langchain.memory import DynamoDBChatMessageHistory
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.agents import initialize_agent
from langchain.agents import AgentType
ssm = boto3.client('ssm')
OPENAI_API_KEY = ssm.get_parameter(Name='OPENAI_API_KEY', WithDecryption=True)['Parameter']['Value']
pinecone_key = ssm.get_parameter(Name='PINECONE_KEY', WithDecryption=True)['Parameter']['Value']
pinecone_env = ssm.get_parameter(Name='PINECONE_ENV', WithDecryption=True)['Parameter']['Value']
pinecone.init(api_key=pinecone_key, environment=pinecone_env)
index = pinecone.Index('openai')
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vectordb = Pinecone(index, embedding_function=embeddings.embed_query, text_key="text")
chat = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
temperature=0,
model_name = "gpt-3.5-turbo-16k",
streaming=True,
callbacks=[FinalStreamingStdOutCallbackHandler()],
)
retriever = RetrievalQA.from_chain_type(
llm=chat,
chain_type="stuff",
retriever=vectordb.as_retriever(),
)
tools = [Tool(
func=retriever.run,
description="Use this tool to answer user questions using AntStack's data. This tool can also be used for follow up questions from the user",
name='AntStack DB'
)]
def chat(session_id, question):
chat_history = DynamoDBChatMessageHistory(table_name='conversation-store', session_id=session_id)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
memory.chat_memory = chat_history
conversational_agent = initialize_agent(
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
tools=tools,
llm=chat,
verbose=False,
memory=memory,
handle_parsing_errors=True,
)
sys_msg = """You are a chatbot for a Serverless company AntStack and strictly answer the question based on the context below, and if the question can't be answered based on the context, say \"I'm sorry I cannot answer the question, contact connect@antstack.com\"
"""
prompt = conversational_agent.agent.create_prompt(
system_message=sys_msg,
tools=tools
)
conversational_agent.agent.llm_chain.prompt = prompt
return conversational_agent.run(question)
def lambda_handler(event, context):
body = json.loads(event['body'])
session_id = body['session_id']
question = body['question']
response = chat(session_id, question)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "*",
"Access-Control-Allow-Methods": "*",
},
"body": response
}
For detailed steps to deploy this application, visit my previous blog. All the steps are same except for installing Docker as we do not need it here.
Before performing sam build and sam deploy, make sure that all the relevant keys are uploaded to Parameter Store in Systems Manager. Visit here to get to know the complete architecture of this SAM Project.
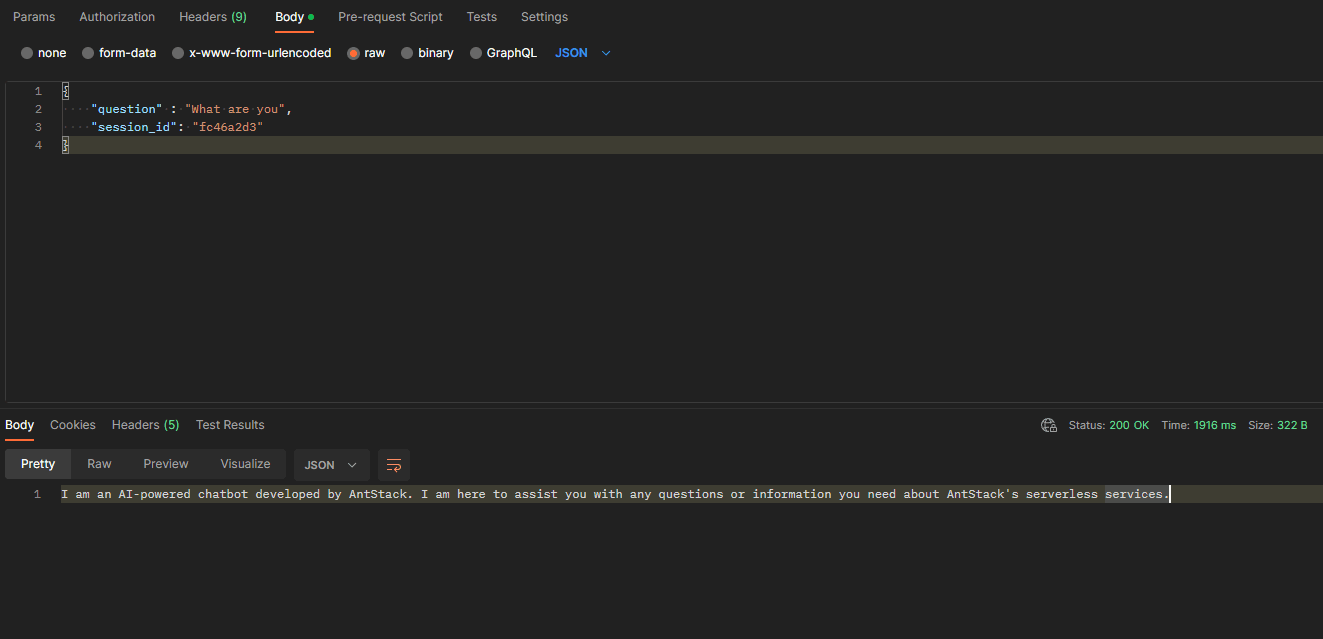
Once the application is deployed, you can test the API Gateway URL with your message and Session ID as the input events to the Lambda.
Here's an example:
Conclusion
We have successfully built a full fledged chatbot which answers a question based on the context fetched from the retriever and stores the conversation in a DynamoDB backed memory. The entire process of building a chatbot like this would be even simpler if you don't need retrieval based QA. There many memory integrations from Langchain other than DynamoDB, check them out here. You can also have a similar implementation with chat memory with basically any agent that you create using Langchain, and it is not limited to our specific use case.
If you liked my blog, or have any feedback, reach out to my Twitter or LinkedIn!











