


 ChatGPT
ChatGPT  Perplexity
Perplexity  Gemini
Gemini  Claude AI
Claude AI We implemented Multi-tenant architecture with Row Level Security (RLS) for one of our clients. The goal was to make sure users could only see the data they were allowed to, based on their organization and role. Setting it up went smoothly, and everything seemed to work well at first.
Simple queries, like fetching a single record, didn’t have much performance impact. But queries that handled larger datasets, like analytics or reports, started slowing down. Tasks that used to finish in milliseconds were now taking seconds, causing dashboards to load slower in the application.
To address this, we began a deep dive into the system, analyzing query plans, testing scenarios, and exploring, how RLS was affecting performance at every level?
For our demonstration we will use a sample database looking something like this:
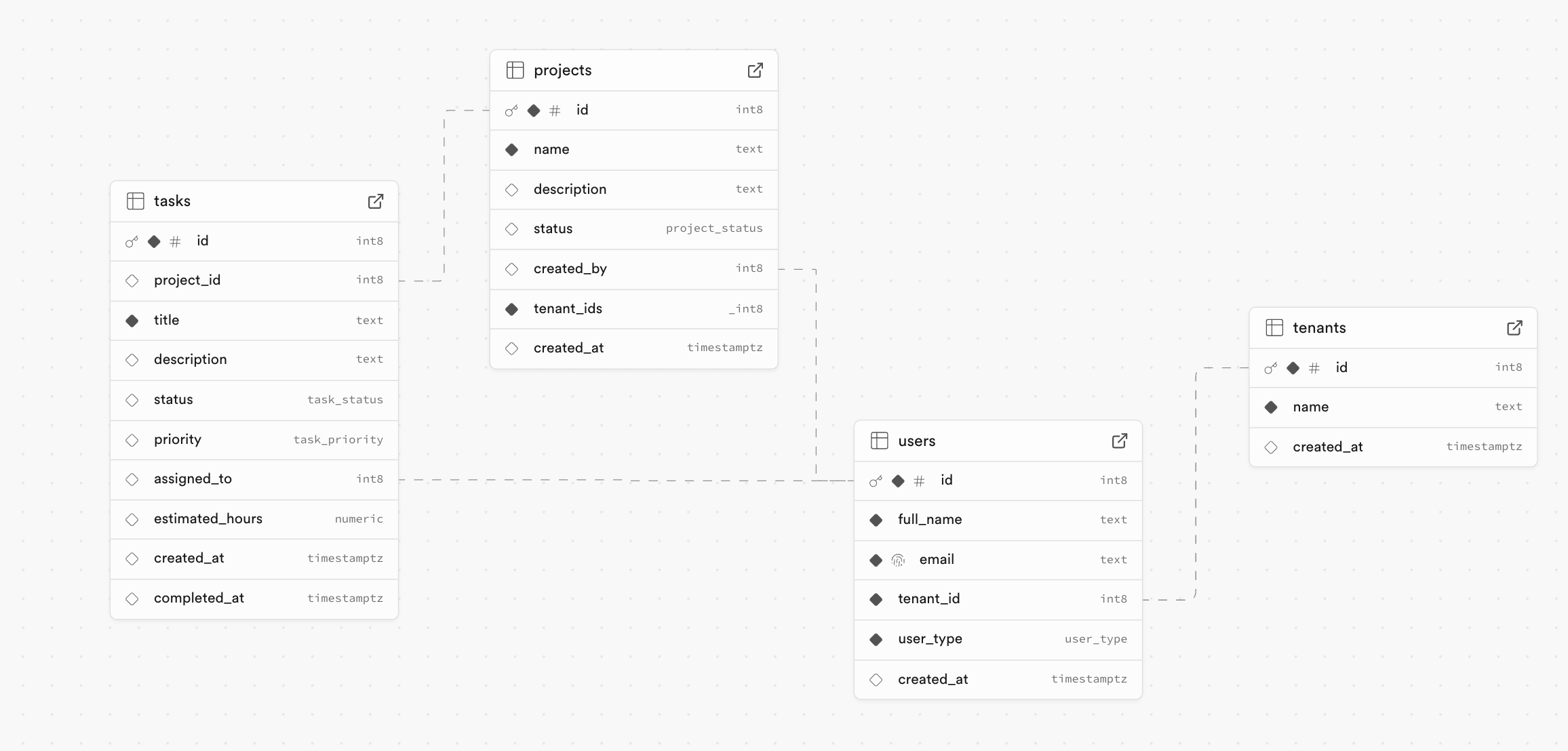
It's a multi-org project management database where each organization can manage its own projects while also having the ability to share projects with other organizations. Tasks within these projects can be assigned to users from the same organization or collaborating organizations. To ensure data isolation and security, we have implemented Row Level Security (RLS). This allows users to only access the data they are authorized to see, maintaining strict separation between organizations while enabling collaboration where needed.
The reference schema and queries used in this blog can be found here: Github repo
Query Performance
We measured query execution times with and without RLS enabled to understand the performance impact. Here are some of the key observations:
| Query Type | Records | RLS Time (ms) | Without RLS (ms) | Degradation |
|---|---|---|---|---|
| Basic Task Selection | 1000 | 182 | 17 | ~11X |
| Project with Task Count | 1000 | 11595 | 6901 | ~2X |
| Project Analytics | 100 | 1242 | 727 | ~2X |
Pattern: As the number of records scanned by a query increases, the performance degrades significantly, resulting in slower execution times.
Optimizing RLS Queries
Indexes
As we dug deeper into the query execution plans, we noticed a key issue. Even though we had indexes on important columns, including tenant_group_ids (an array field with B-Tree indexes), the database wasn't using them when executing queries with RLS enabled. Instead, it was performing a Sequential Scan (Seq Scan), ignoring the indexes completely.
This was surprising because these indexes were supposed to speed up queries. However, the indexes were not picked up, and the performance suffered. Sequential scans are much slower for large datasets, which explains why our queries were taking so long.
We looked into why the indexes weren't being used and explored different types of indexes. Specifically, we focused on optimizing queries involving array columns, since some of our RLS conditions relied on array operations. We found that B-Tree indexes work well for equality and range queries but aren't ideal for array operations, like checking if an element exists in an array. For these cases, GIN (Generalized Inverted Index) indexes are a better fit. GIN indexes are designed for complex queries like those involving arrays or full-text searches and can quickly check if an element is in an array. This made GIN a good option to replace the B-Tree index and potentially improve performance.
We modified the existing B-Tree index on the array column(tenant_group_ids) to a GIN index. The database started picking up the index for query execution, and the performance of our aggregate queries improved significantly. Queries that previously relied on slow sequential scans were now utilizing the GIN index, reducing execution times and making the system far more responsive.
| Query Type | Records | Avg. Execution Time (ms) | Improvement % |
|---|---|---|---|
| Basic Task Selection | 1000 | 165 | 9.3% |
| Project with Task Count | 1000 | 11207 | 3.3% |
| Project Analytics | 100 | 975 | 21.5% |
Encouraged by these results, we began exploring other optimization techniques to further enhance performance.
Immutable Functions
While exploring different techniques to improve query performance, we came across immutable functions. An immuatable functions cannot modify the database and always produce the same result for the same input. Because they don't alter external data, they are safe to use in parallel and concurrent environments, minimizing the risk of unexpected side effects.
However, the RLS policies we were using involved complex operations, such as nested JSON operations and type casting (e.g., ::json ->> 'key' and ::text[]), which created significant overhead. For example, the following policy extract checks the user type and verifies if the user’s tenant_group_ids array overlaps with the tenant_group_id array:
CASE
WHEN (((current_setting('request.jwt.claims'::text, true))::json ->> 'type'::text) = 'tenant'::text)
THEN ((((current_setting('request.jwt.claims'::text, true))::json ->> 'tenant_group_ids'::text))::bigint[] && tenant_group_id)
ELSE false
END
These operations were applied to every row in large datasets, slowing down queries. The repeated extraction and casting of values added unnecessary complexity, especially impacting aggregate queries on large datasets.
To address this, we created an immutable function to simplify the extraction of JWT data, reducing overhead and improving performance. Here's an example:
Example Function:
CREATE OR REPLACE FUNCTION schema_name.get_jwt_claim(claim_key text)
RETURNS text
LANGUAGE plpgsql
IMMUTABLE
AS $function$
BEGIN
RETURN (current_setting('request.jwt.claims', true)::json ->> claim_key);
END;
$function$;
| Query Type | Records | Avg. Execution Time (ms) | Improvement % |
|---|---|---|---|
| Basic Task Selection | 1000 | 75 | 54.5% |
| Project with Task Count | 1000 | 7784 | 30.5% |
| Project Analytics | 100 | 924 | 2.5% |
Since PostgreSQL can cache the results of immutable functions, using them helps speed up aggregate queries by reducing the need to repeatedly process the same data.
SELECT Optimization
Wrapping function calls in SELECT statements, allows PostgreSQL to compute these values once and reuse them throughout the query. This method works well for functions like auth.uid() and auth.jwt(), as well as other functions. By wrapping the function in SQL, we triggered the optimizer to run an initPlan, which allowed it to "cache" the results, instead of calling the function for each row. It’s important to note that this only works if the query or function’s results don’t change based on row data.
For example, instead of using is_admin() OR auth.uid() = user_id in the RLS condition, we used (select is_admin()) OR (select auth.uid()) = user_id, which reduced function executions and improved performance.
| Query Type | Records | Avg. Execution Time (ms) | Total Improvement % |
|---|---|---|---|
| Basic Task Selection | 1000 | 71 | 61.0% |
| Project with Task Count | 1000 | 4980 | 57.0% |
| Project Analytics | 100 | 1046 | 15.8% |
This reduced function executions, resulting in better performance.
Conclusion
The performance improvements for query types are as follows: Basic Task Selection improved by 61%, Project with Task Count by 57%, and Project Analytics by 15.8%, significant gains in database query efficiency, particularly for simpler tasks.
The strategies outlined here significantly improved the performance of PostgreSQL (Supabase) queries. By optimizing RLS policies and refining query structures, we enhanced the overall system performance. For additional insights and strategies on optimizing PostgreSQL, check out this Supabase discussion link.












